Linux Eventfd Overview
An “eventfd object” can be used as an event wait/notify mechanism by user-space applications, and by the kernel to notify user-space applications of events. It has been added to kernel since Linux 2.6.22. And the object contains an unsigned 64-bit integer (uint64_t) counter that is maintained by the kernel. So it’s extremely fast to access.
1 2 | |
That’s all we need to create one eventfd file, after that, we can perform normal file operations (like read/write, poll and close) with it.
Once some user-space thread write it with value greater than 0, it will instantly be notified to user-space by kernel. Then, the first thread which read it, will reset it (zero its counter), i.e. consume the event. And all the later read will get Error (Resource Temporarily Unavailable), until it is written again (event triggered). Briefly, it transforms an event to a file descriptor that can be effectively monitored.
There’re several notes of which we should take special account:
Applications can use an eventfd file descriptor instead of a pipe in all cases where a pipe is used simply to signal events. The kernel overhead of an eventfd file descriptor is much lower than that of a pipe, and only one file descriptor is required (versus the two required for a pipe).
As with signal events, eventfd is much more light-weight (thus fast) compared to the pipes, it’s just a counter in kernel after all.
A key point about an eventfd file descriptor is that it can be monitored just like any other file descriptor using select(2), poll(2), or epoll(7). This means that an application can simultaneously monitor the readiness of “traditional” files and the readiness of other kernel mechanisms that support the eventfd interface.
You won’t wield the true power of eventfd, unless you monitor them with epoll (especially EPOLLET).
So, let’s get our hands dirty with an simple worker thread pool!
Worker Pool Design
We adopt Producer/Consumer pattern for our worker thread pool, as it’s the most common style of decoupling, achieving the best scalability. By leveraging the asynchronous notification feature from the eventfd, our inter-thread communication sequence could be described as following:

Implementation
Our per-thread data structure is fairly simple, only contains 3 fields: thread_id, rank (thread index) and epfd which is the epoll file descriptor created by main function.
1 2 3 4 5 | |
Consumer thread routine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
As we can see, the worker thread get the notification by simply polling epoll_wait() the epoll-added fd list, and read() the eventfd to consume it, then close() to clean it.
And we can do anything sequential within the do_task, although it now does nothing.
In short: poll -> read -> close.
Producer thread routine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
In producer routine, after creating eventfd, we register the event with epoll object by epoll_ctl(). Note that the event is set for write (EPOLLIN) and Edge-Triggered (EPOLLET).
For notification, what we need to do is just write 0x1 (any value you want) to eventfd.
In short: create -> register -> write.
Source code repository: eventfd_examples
Output & Analysis
The expected output is clear as:
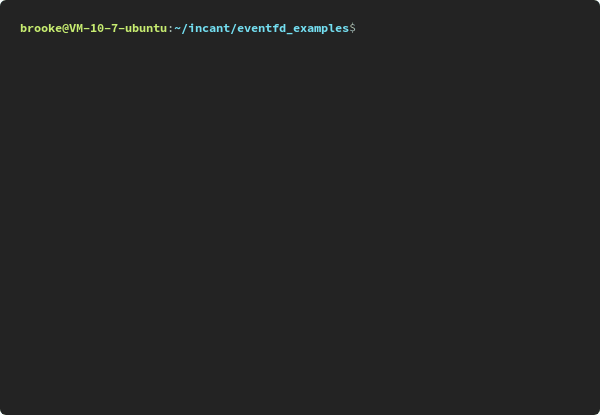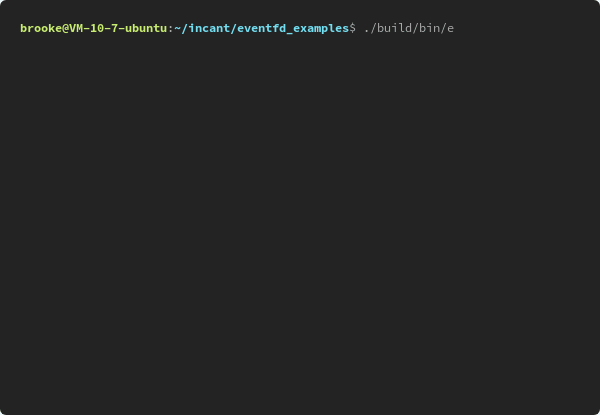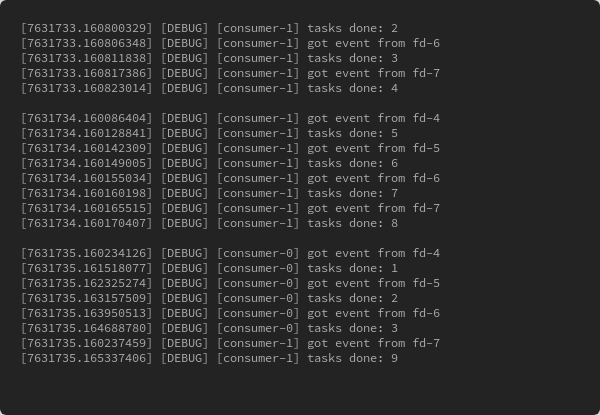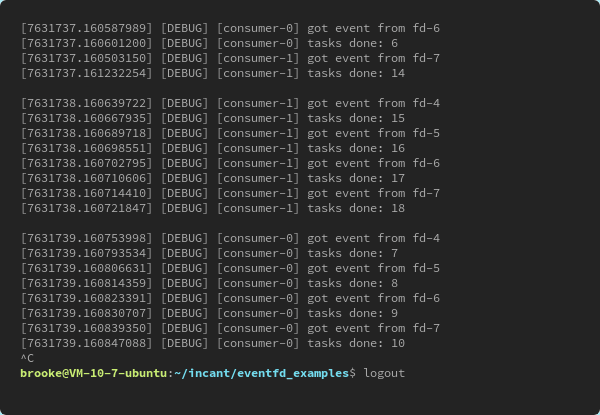
You can adjust threads number to inspect the detail, and there’s a plethora of fun with it.
But now, let’s try something hard. We’ll smoke test our worker by generate a heavy instant load, instead of the former regular one. And we tweak the producer/consumer thread to 1, and watching the performance.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Over 1 million? Indeed! By using the ulimit command below, we can increase the open files limit of the current shell, which is usually 1024 by default.
Note that you need to be root.
1 2 3 4 5 | |
Since the info of stdout is so much that we redirect the stdout to file log.

With my test VM (S2.Medium4 type on TencentCloud, which has only 2 vCPU and 4G memory, it takes less than 6.5 seconds to deal with 1 million concurrent (almost) events. And we’ve seen the kernel-implemented counters and wait queue are quite efficient.
Conclusions
Multi-threaded programming model is prevailing now, while the best way of scheduling (event trigger and dispatching method) is still under discussion and sometimes even opinionated. In this post, we’ve implemented general-purposed worker thread pool based on an advanced message mechanism, which includes:
- message notification: asynchronous delivering, extremely low overhead, high performance
- message dispatching: as a load balancer, highly scalable
- message buffering: as message queue, with robustness
All the above are fulfilled by using basic Linux kernel feature/syscall, like epoll and eventfd.
Everyone may refers to this approach when he/she designs a single-process performant (especially IO-bound) background service.
To sum up, taking advantage of Linux kernel capability, we are now managed to implement our high-performance message-based worker pool, which is able to deal with large throughput and of high scalability.